哈尔滨工程大学——语料库智能检索系统——后端仓库
”人工智能 信息检索 语料库 python“ 的搜索结果

2,基于词袋模型和TFIDF模型,采用余弦相似度作为度量标准,对测试问题语料库中的问题进行文本相似度计算,找出相似度较高的问题作为相似问题集合。 3,将相似问题集合中的问题进行排序,同时返回其对应的答案给...
内容简介自然语言处理是计算语言学和人工智能之中与人机交互相关的领域之一。 本书是学习自然语言处理的一本综合学习指南,介绍了如何用Python实现各种NLP任务,以帮助读者创建基于真实生活应用的项目。全书共10章,...

语料库的搭建setMySQL.py 语料库使用MySQL搭建 所有关于MySQL的查询操作均集成于此文件 MySQL环境要求: 用户名:root 密码:12345678 数据库名称:mySearchDB 表单名称:WorkSpace 环境配置时只需要数据库存在,表单...
2、本项目适合计算机相关专业(如计科、人工智能、通信工程、自动化、电子信息等)的在校学生、老师或者企业员工下载学习,也适合小白学习进阶,当然也可作为毕设项目、课程设计、作业、项目初期立项演示等。...

这章笔记一步步介绍语料库概念与使用,安装NLTK,实现对线上语料库内容的获取与分析,最后实现构建一个斗罗大陆小说的本地语料库。
NLP浅谈语料库 1. 浅谈语料库 1.1 预料和语料库 语料通常指在统计自然语言处理中实际上不可能观测到大规模的语言实例。所以人们简单地用文本作为替代,并把文本中的上下文关系作为现实世界中语言的上下文关系的...

北京 上海巡回站 | NVIDIA DLI深度学习培训2018年1月26/1月12日NVIDIA 深度学习学院 带你快速进入火热的DL领域阅读全文 >作者:刘艺原,现浙江大学 生物医学工程研究生。正文共5788个字,5张图,预计阅读时间:15...

基于chatterbot和wiki语料库实现检索式聊天机器人


基于百度中文问答数据集WebQA构建问答机器人,共45247条数据。属于检索式问答系统,采用倒排索引+TFIDF+余弦相似度。速度极快。
结巴”中文分词:做最好的 Python 中文分词组件开发者可以指定自己自定义的词典,以便包含 jieba 词库里没有的词。虽然 jieba有新词识别能力,但是自行添加新词可以保证更高的正确率用法: jieba.load_userdict(file...
利用该工具可以方便的获得各项NLP任务需要的标注语料。以下是利用该工具进行命名实体识别任务的标注例子。 WeTest舆情团队在使用:http://wetest.qq.com/bee/ 使用案例:http://blog.csdn.net/...
该库是对目前市面上已有的开源中文聊天语料的搜集和系统化整理工作 该库搜集了包含 - chatterbot - 豆瓣多轮 - PTT八卦语料 - 青云语料 - 电视剧对白语料 - 贴吧论坛回帖语料 - 微博语料 - 小黄鸡语料 ...
质量保证 为开放域QA和IR预训练密集语料库索引的资源有效方法。 给定问题,您可以使用此代码从Wikipedia检索相关段落并提取答案。 1.设置环境 conda create -n proqa -y python=3.6.9 && conda activate proqa pip ...
实作这个聊天机器人是用Python3编写的,主要使用: NLTK:是自然语言处理(NLP)和人工智能库。 NLTK用于文本预处理(消除噪声,停用词,词干和词形去除)。 请访问了解更多信息。 scikit-learn:是一个数据挖掘和...
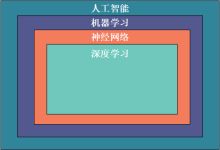
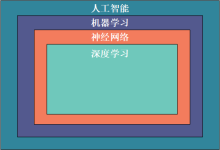
人类一直试图让机器能够智能化,能有自主学习的能力,也就是人们常说的人工智能。从上世纪50年代,人工智能就开始了“推理期”;到70年代,人工智能的发展进入“知识期”;直到现在,人工智能在越来越多的领域深入...
人工智能已经深深融入到我们的生活,作为构建智能应用的基石。而Python凭借其简单易用的语法以及强大的生态,成为AI开发者手中的利器。今天,我就为大家推荐15个AI与Python紧密结合、功能强大的第三方库。这些库涵盖了...

推荐文章
- 用好ASP.NET 2.0的URL映射-程序员宅基地
- C语言等级考试是把题目删了,历年全国计算机的等级考试二级C语言上机考试地训练题目库及答案详解(72页)-原创力文档...-程序员宅基地
- Microsoft Office显示正在更新无法打开的问题_正在更新microsoft 365和office-程序员宅基地
- 非常好的Ansible入门教程(超简单)-程序员宅基地
- 【Gradle-8】Gradle插件开发指南-程序员宅基地
- 使用PL/SQL Developer软件解锁_plsqldev表格锁怎么打开-程序员宅基地
- 【Windows Server 2019】Web服务 IIS 配置与管理——配置 IIS 进阶版 Ⅳ_iis默认路径-程序员宅基地
- 网络中的各层协议_发送消息时各层协议-程序员宅基地
- UCRT: VC 2015 Universal CRT, by Microsoft_vc15rt-程序员宅基地
- 关于EntityFramework 7 开发学习_entiry framework 7 书籍-程序员宅基地